
Technologien
Künstliche Intelligenzen
März 2022
Künstliche Intelligenz (KI) ist eine treibende Kraft für die Entwicklung innovativer medizinischer Produkte. Die Anwendung von Big-Data-Ansätzen ist aber aufgrund der begrenzten Grösse typischer medizinischer Datensätze nicht erfolgsversprechend. Trotzdem können medizinische Anwendungen mit begrenzten Datensätzen zu einer Erfolgsgeschichte werden. Entscheidend ist, die richtigen Techniken anzuwenden. Mit der Erfahrung, dem Know-how und den Werkzeugen von Helbling wird aus der Herausforderung eine Erfolgsstory.
Immer mehr Kunden von Helbling insbesondere aus dem medizinischen Bereich machen die Erfahrung, dass die Beschaffung grosser Datenmengen teuer und zeitaufwändig ist. Die Gründe für die Schwierigkeiten sind vielfältig: Unter anderem sind die Dauer und Kosten klinischer Studien – inklusive der Genehmigung durch eine Ethikkommission – hoch; es werden zudem teure Geräte und Experten für die Annotation der Daten benötigt. Das hält auch einige kleine oder mittlere Unternehmen davon ab, KI in ihre Produkte zu integrieren. Helbling hat bereits in vielen Fällen erfolgreich Techniken angewendet, die den Einsatz von leistungsfähiger KI im medizinischen Bereich trotz begrenzter Datenmengen ermöglichen. Die in den folgenden Abschnitten vorgestellten Techniken verbessern die Leistung von KI-Modellen für Anwendungen mit begrenzten Datenmengen erheblich und werden anhand von Projekten illustriert, an denen Helbling beteiligt war. Aus Gründen der Vertraulichkeit basieren die Abbildungen auf öffentlich zugänglichen Quellen.
Technik 1: Reduzierung der Modellkomplexität zur Verringerung der erforderlichen Datenmenge
Die für das Training benötigte Datenmenge korreliert mit der Modellkomplexität, welche durch die Anzahl der Modellparameter repräsentiert wird. Die Anzahl der Parameter kann jedoch reduziert werden. Erreicht wird dies, indem der Leistungsumfang des Modells begrenzt wird oder extrahierte Merkmale anstelle von Rohdaten verwendet werden.
Technik 2: Künstliche Erweiterung der Datenmenge und -variabilität (Data Augmentation)
Bei der Data Augmentation werden die Datenmenge und -variabilität künstlich erweitert. Bei dieser Technik werden leicht veränderte Kopien vorhandener Daten hinzugefügt oder neue synthetische Daten generiert. Methoden zur Datenerweiterung werden mittels Fachwissen und im Anwendungskontext ausgewählt. Der Einsatz von Data Augmentation wird hier erläutert anhand eines Projektes zur Hautkrebsdiagnose durch Bildanalyse, bei welchem Helbling als Entwicklungspartner involviert war.
Um die Variabilität der Bilder zu erweitern und die Genauigkeit der Bildklassifikation zu erhöhen, kommen in diesem Beispiel drei Arten von Bildtransformationen zum Einsatz. Erstens werden Bildtransformationen verwendet, um Variationen der Bildgebung einzuführen, etwa durch das Hinzufügen von Bildrauschen, Reduzieren des Bildkontrasts, Ändern des Umgebungslichts oder der Homogenität der Beleuchtung. Zweitens werden Bildtransformationen verwendet, um benutzerinduzierte Variabilität hinzuzufügen. Die Variabilität umfasst Bewegungsunschärfe und verschiedene Geräteausrichtungen. Drittens werden die Eigenschaften des Objekts verändert. Im Beispiel der Hautkrebsdiagnose können Haare hinzugefügt oder kann die Hautfarbe verändert werden.
Die Kombination der vorgestellten Bildtransformationen erhöht die Variabilität weiter. Wichtig ist, dass die Bildtransformationen die Klasse des Objekts wie zum Beispiel „bösartiges oder gutartiges Muttermal“ nicht verändern. Lediglich das Aussehen soll sich ändern.

Technik 3: Transfer Learning, um von anderen Datenquellen und/oder ähnlichen Problemen zu profitieren
Transfer Learning ist der Prozess der Anwendung von Wissen aus einem gelösten Problem auf ein neues Problem. Die beiden Probleme müssen miteinander verwandt sein, damit das Transferlernen effektiv ist.
Eine Form des Transfer Learning ist es, bereits trainierte Schichten eines etablierten neuronalen Netzes zu verwenden und eine Teilmenge der Schichten für eine neue Aufgabe neu zu trainieren. Ein Beispiel für ein öffentlich verfügbares und weit verbreitetes neuronales Netz ist das Alexnet [2], ein Convoluational Neural Network mit acht Schichten, die anhand von 14 Millionen Bildern trainiert worden sind.
Eine andere Form des Transfer Learnings ist die Kombination eines kleinen verfügbaren Datensatzes mit Daten, die von einem anderen Gerät erfasst wurden. Diese Technik wird auch als Domain Adaption bezeichnet. Helbling hat Transfer Learning in einem Projekt im Bereich der Augenheilkunde eingesetzt. Wie in Abbildung 2 dargestellt, wurden hochaufgelöste Bilder, die mit einem handelsüblichen Gerät aufgenommen wurden, künstlich degradiert. Die Bilder sollen aussehen, als seien sie mit dem in der Entwicklung befindlichen Produkt aufgenommen worden. Die degradierten Bilder werden verwendet, um die Menge und die Vielfalt der Trainingsdaten zu vergrössern.
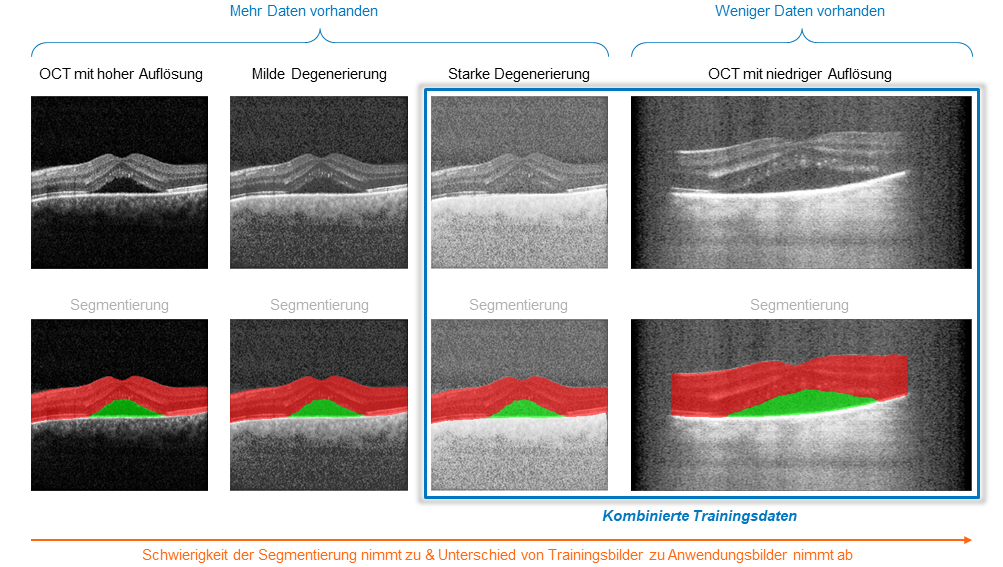
Besonderheit: Umgang mit unausgewogenen Datensätzen
In einem unausgewogenen Datensatz sind die meisten Datenpunkte Teil einer Klasse, während andere Klassen unterrepräsentiert sind, zum Beispiel weisen bei der Qualitätskontrolle nur wenige Teile einen Fehler auf. Unausgewogene Datensätze erschweren das Lernen der unterrepräsentierten Klasse, welche in vielen Anwendungen die interessierende Klasse ist.
Eine erste Möglichkeit besteht darin, synthetisch neue Datenpunkte der unterrepräsentierten Klasse zu erzeugen, etwa durch Synthetic Minority Oversampling (SMOTE) [5]. SMOTE erzeugt künstlich neue Datenpunkte durch Interpolation zwischen zwei oder mehr vorhandenen Datenpunkten. Diese Technik funktioniert gut bei skalaren Daten und ist für Bilddaten weniger geeignet.
Eine zweite Möglichkeit eignet sich für die binäre Klassifizierung. Dabei werden nur Datenpunkte der Mehrheitsklasse verwendet. Durch das Training eines neuronalen Netzes können Abweichungen von der Mehrheitsklasse erkannt werden. Die folgende Abbildung veranschaulicht das Funktionsprinzip eines so genannten Variational Autoencoders [6] zur Erkennung von Defekten an Stents.
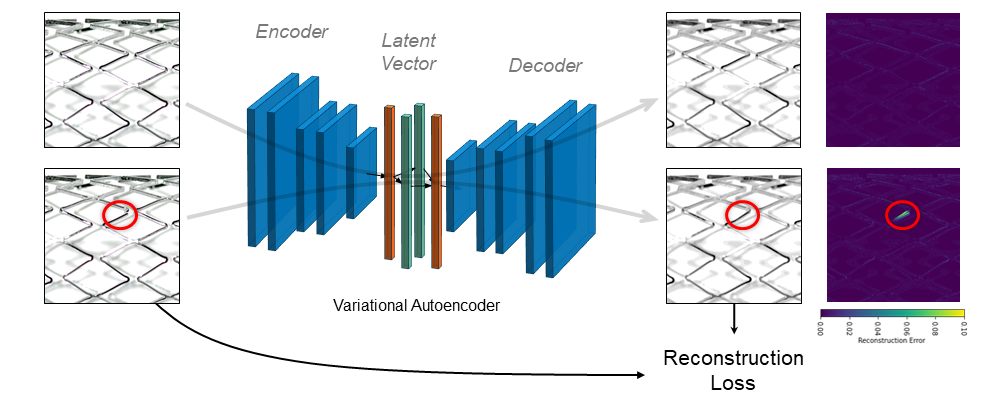
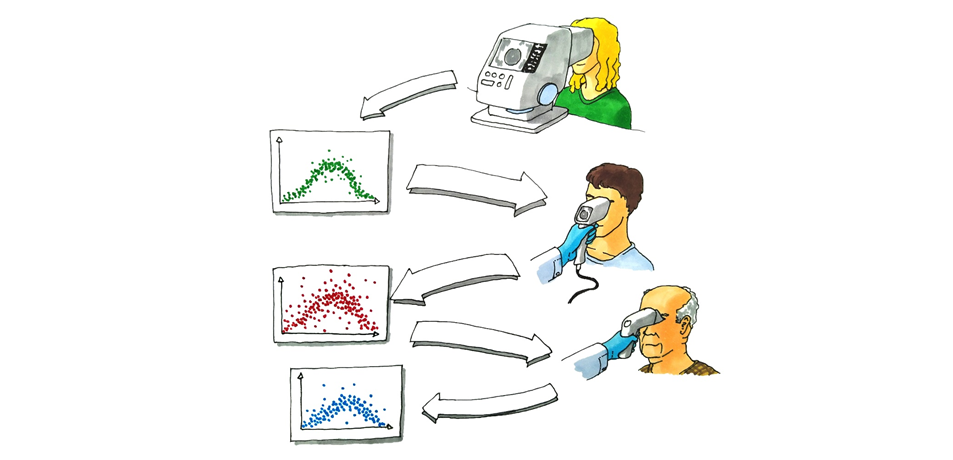
Besonderheit: Evolution der Messtechnik während der Entwicklung
Um die Zeit bis zur Markteinführung zu minimieren und die erreichbare Leistung frühzeitig beurteilen zu können, müssen die Messtechnik und das KI-Modell durch ihre gegenseitige Abhängigkeit parallel entwickelt werden. Während der Entwicklung werden hierbei verschiedene Datenquellen verwendet. In der Vergangenheit nutzte Helbling öffentlich verfügbare Daten, die auf ähnlichen Messtechniken basieren, oder simulierte Daten, bis die Messtechnik entwickelt ist. Es ist ebenfalls möglich, mit Daten von bestehenden Produkten zu arbeiten, die auf gleichen oder ähnlichen Messtechnologien basieren. Schliesslich werden für die Entwicklung von KI-Modellen auch Daten verwendet, die mit verschiedenen Entwicklungsprototypen gewonnen wurden. Ein wichtiger Aspekt ist, dass die Bewertung der KI-Zwischenmodelle die Entwicklung der Messtechnik beeinflusst. Das betrifft etwa die erforderliche Auflösung oder die Bildstabilisierung (akzeptable Bewegungsunschärfe).
Zusammenfassung: Helbling ermöglicht KI mit limitierten Datensätzen durch fundiertes Fachwissen
Ein Schlüsselfaktor für die erfolgreiche Anwendung der vorgestellten Techniken zur Entwicklung von KI-Modellen mit begrenzten Datensätzen ist Fachwissen. Dazu gehören medizinisches Wissen und das Verständnis der physikalischen Prozesse und der Benutzerinteraktionen. Auf dieser Grundlage kann die Modellkomplexität reduziert, die Datenmenge und -variabilität künstlich erweitert und das Transfer Learning angewendet werden. Zusätzlich kann eine effiziente Entwicklung mit unausgewogenen Datensätzen umgehen und das KI-Modell parallel zur Messtechnik weiterentwickeln. Dadurch werden auch anspruchsvolle Time-to-Market-Ziele erreicht. Helbling entwickelt KI-Anwendungen, indem es interne und externe Wissensnetzwerke voll ausschöpft.
Autoren: Matthias Pfister, Urs Anliker, Cyril Stoller, Simon Kurmann
Hauptbild: metamorworks via istockphoto
Referenzen
[1] International Skin Imaging Collaboration (“ISIC”), www.isic-archive.com
[2] Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton (2017-05-24). "ImageNet classification with deep convolutional neural networks". Communications of the ACM. 60 (6): 84–90. doi:10.1145/3065386. ISSN 0001-0782. S2CID 195908774
[3] von der Burchard, Claus, et al., Self-examination low-cost full-field OCT (SELFF-OCT) for patients with various macular diseases., 2021
[4] https://creativecommons.org/licenses/by/4.0/, February 2, 2022
[5] N.V. Chawla et al., SMOTE: Synthetic Minority Over-sampling Technique, Journal Of Artificial Intelligence Research, Volume 16, pages 321-357, 2002
[6] D.P. Kingma et al., Auto-Encoding Variational Bayes, arXiv preprint arXiv:1312.6114, 2013




